
2009-04-28 13:00:00
Time and Space Tradeoffs in Version Control Storage
Storage is one of the most difficult challenges for a version control system. For every file, we must store every version that has ever existed. The logical size of a version control repository never shrinks. It just keeps growing and growing, and every old version needs to remain available.
So, what is the best way to store every version of everything?
As we look for the right scheme, let's remember three things we consider to be important:
- Data integrity is paramount. In a version control tool,
nothing can be considered to be more important than guarding the safety of
the data.
- Performance is critical. Software developers have about
as much patience as a German Shepherd sitting in front of a pot roast.
- Space matters too. We're going to be storing lots of data, much of which is being kept almost entirely for the purpose of archiving history. We'd prefer to keep this archive as compact as possible.
In this blog entry I will report the results of some exploration I've been doing. I am experimenting with different ways of storing the full history of one source code file. In this case, the file comes from the source code for SourceGear Vault. It has been regularly edited for almost seven years. There are 508 versions of this file.
As I describe the various things I have tried, a running theme will be the classic tradeoff of space vs. speed. In physics, we know that matter and energy are interchangeable. In computer science, we know that time and space are interchangeable. Usually, we can find a way to make things faster by using more space, or make things smaller by taking more time.
As I said, I'll be storing 508 versions of the same file. It's a C# source code file. For each attempt, I will report two things:
- The total amount of space required to store all 508
versions.
- The total amount of time required to retrieve (or decompress or decode) all 508 versions, one at a time.
Before we get started, a few caveats:
- I realize that these experiments would yield different
results for a different kind of file. If you're storing source code,
there might be some things here you can apply. If you're storing JPEG
images, not so much.
- All these experiments were done on my Mac Book Pro laptop. The CPU is a Core 2 Duo, which I consider to be decently fast. But like most laptops, this machine has an I/O system which I consider to be quasi-crappy. I would probably get somewhat different results if I were running on a more serious piece of hardware.
OK, how should we store these 508 versions of the file?
No compression at all
As a first attempt, let's just store them. No compression or funky encoding. Each of the 508 versions will be stored in full and uncompressed form.
This is the starting point, even if it is not very practical.
Size: 112,643 KB
Time: 2.5 s
#ifdef DIGRESSION
Yes, dear reader, I admit that this file is far too long.
You can do the math. If the archive takes 112 MB and there are 508 versions, then each one is 230 KB. That's pretty big for a source code file.
Actually, it's worse than you think. The 230 KB figure is just the average. The first version of the file is around 90 KB. The latest version is over 400 KB.
In our defense, I'd like to point out that this piece of code needs to stay compatible with .NET 1.1, so the entire class must be in a single file. However, I'd still have to answer to the charge of "First Degree Failure to Refactor". Fine. I'll have my attorney contact you to plead out on a lesser charge. I'm thinking maybe "Third Degree Contributing to the Delinquency of an Intern", or something like that.
#endif
This "full and uncompressed" format uses an awful lot of space, but it is also the fastest. We will find ways of making this smaller, but all of those ways will be slower.
The relevant questions are:
- How much smaller?
- How much slower?
Some solutions will allow us to make this a lot smaller and only a little slower. Those are interesting. Other possibilities will be only a little smaller but a lot slower. Those are not so interesting.
Simple compression
OK, for our next idea, let's just compress every version with zlib.
Size: 22,516 KB
Time: 4.0 sec
The results of this idea are surprisingly impressive. The archive is over 80% smaller, and only about 60% slower. That's darn good, considering that I didn't have to be terribly clever.
This tradeoff is probably worth it. In fact, it establishes a new baseline that might be tough to beat.
How do we get better than this?
Deltas
Instead of just compressing every file independently, we could store things as deltas. Think of a delta as simply the difference between one version and the next.
Compression with zlib takes one standalone thing and makes an equivalent standalone thing which is smaller.
In contrast, a delta is a representation of the differences between two files. Suppose that somebody takes file X and makes a few changes to it, resulting in file Y. With a delta algorithm, we could calculate the delta between X and Y, and call it D. Then, instead of storing Y, we can store D.
The nice thing here is that D will be approximately the size of the edits, regardless of the size of the two files. If X was a 100 MB file and Y was the same file with an extra 50 bytes appended to the end, then D will be somewhere around 50 bytes,
A delta is a concept which might be implemented in a lot of different ways. In my case, the delta algorithm I am using is VCDIFF, which is described in RFC 3284. We have our own implementation of VCDIFF. Other implementations include xdelta and open-vcdiff.
The important thing to remember about deltas for storage is that you must have the reference item. D is a representation of Y, but only if you have X handy. X is the reference.
OK, it should be obvious that this concept can be helpful in storing a repository, but how do we set things up?
One big delta chain
As a first attempt, let's store all 508 versions as a big chain of deltas. Every version is stored as a delta against the version just before it. Version 1 is the reference, and is the only version that is not stored as a delta.
Size: 7,682 KB
Time: Way too long to wait
Wow -- this is really small. It's over 93% smaller than the full/uncompressed form. It'll be hard to find a general purpose approach that is smaller than this.

But good grief this is slow. Fetching version 508 takes an eternity, because first you have to construct a temporary version of 507. And to construct version 507, you first have to construct a temporary version of 506. And so on.
Key frames
Let's try something else. The problem with the chaining case above is that retrieving version 508 requires us to go all the way back to version 1, which is incredibly inefficient. Instead, let's insert "key frames" every 10 versions. We borrow this idea from the video world where compressed video streams store every frame as a delta, but every 10 seconds they insert a full, uncompressed frame of video.
By using key frames with chaining deltas, we can cut the time required to fetch the average version of the file. For example, with a key frame every 10 versions, we get most of the benefits of chaining, but in the worst case, we only need 9 delta operations to retrieve any version.
Size: 18,024 KB
Time: 41.0 sec
This is better, but still not very good. The compression here isn't much better than zlib, and the perf is still a lot worse. Compared to zlib, we don't want to pay a 10x speed penalty just to get 20% better compression.
All the key frames are stored as full and uncompressed files, and they're taking up a lot of space. Maybe we should zlib those key frames?
Size: 9,092 KB
Time: 42.7 sec
Now at least the compression is starting to look interesting. This is less than half the size of the zlib case, and 91.9% smaller than the full form, which is a level of compression that is probably worth the trouble. But the overall perf is still quite slow. In fact, it's even slower here than plain chaining with key frames, because we have to un-zlib the key frame.
Flowers
The big problem here is that chains of deltas are killing our performance. Chained deltas can be used to make things very small because each delta matches up nicely with one set of user edits. But chained deltas are slow because we need multiple operations to retrieve a given file.
Another approach would be to use each reference for more than one delta. I call this the flower approach. With a flower, we deltify a line of versions by picking one version (say, the first one) and using it as the reference to make all the others into deltas.
Flower deltas should be much faster, since any file can be reconstructed with just one undeltify operation.
So let's try to flower all 508 versions using version 1 as the reference for all of them.
Size: 35,851 KB
Time: 10.9 sec
As expected, the performance here is much better.
But the overall space savings is lousy. Only version 2 was based directly on version 1. Every version after that has less and less in common with version 1, so the delta algorithm can't draw as much stuff from the reference.
This particular approach isn't going to win. Plain zlib is both smaller and faster.
Flowers with key frames
Maybe we should try the flower concept with key frames?
Like before, every 10 frames go together as a group. But instead of chaining, we're going to run each group as a flower. The first version in the group will serve as the reference for the other 9. We can reasonably assume that the deltification of frame 10 won't be as good as frame 2, but hopefully 10 and 1 still have enough in common to be worthwhile.
Size: 18,648 KB
Time: 12.2 sec
Wow. This looks a lot better than chaining. The space used is about 17% smaller than zlib, but instead of being 10 times slower, it's only 3 times slower.
Of course, we can use the same trick we tried before. Let's zlib all those key frames.
Size: 9,716 KB
Time: 13.6 sec
This seems like a potentially useful spot. It's less than half the size of zlib. The perf still a lot slower than zlib, but at only about 3X slower, the tradeoff is the best we've seen so far.
OK. So we've made a lot of progress on saving space, but 3X slower than zlib still seems like a high price to pay. Do we really want to make that trade? Do we have to?
Some things get retrieved more often than others
Let's look at the patterns for how this data is going to be accessed.
I've been reporting the total time required to fetch all 508 versions of the file. However, this benchmark doesn't reflect real usage very well at all. In practice, the recent stuff gets retrieved a LOT more often than the older stuff. Most of the time, developers are updating their working copy to whatever is latest.
As a rough guess, I'm going to say that version 508 gets retrieved twice as often as 507, which gets retrieved twice as often as 506, and so on. A timing test based on that assumption gives us results something like this:
Full 1.1 sec
Zlib 1.7 sec
One big flower 4.0 sec
Flower with key frames 5.1 sec
Chain with key frames 24.5 sec
Not too surprising.
In the spirit of optimizing performance for the most common operations, why not keep all the more recent versions in a faster form? We could still use something more aggressive for the older stuff, but we can probably get a nice performance boost if we just refuse to use deltification for the most recent 10 versions of the file.
But how should we store those 10 versions? In full format? Or zlib? This is an arbitrary choice with a clear tradeoff. For now, I choose zlib. If we wanted a little more speed at the expense of using a little more space, we could just keep those 10 versions in full form.
By choosing zlib for the most recent 10 revisions, now my "get the recent stuff" benchmark runs in 1.7 seconds no matter what scheme I use.
But we still care about performance for the case where somebody fetches an older version, even if that fetch doesn't happen as often. That's the point of version control storage. Every version has to be available. And when somebody does fetch version 495, we want our version control system to still be reasonably fast.
Reversing the direction of the chains
Since the more recent versions are retrieved more often, obviously, our chains are all going the wrong direction. If we had them go the other way, then retrieval would get slower as the versions get older instead of as the versions get newer.
But this approach doesn't lend itself well to the way version control repositories naturally grow in the wild. In these tests, I have mostly ignored the issues of constructing each storage scheme. I've already got all 508 versions, so I'm just fiddling around with different schemes of storing them all, comparing size and retrieval time.
In practice, those 508 versions happened one at a time, in order. If we're going to store the versions with backward chains, then each time we commit a new version of the file, we're going to need to re-encode something that was previously stored. This makes the commit operation slower. It is also a questionable idea from the perspective of data integrity. The safest way to maintain data is to not touch it after it has been written. Once it's there, leave it alone.
One case where we might want to be a bit more liberal toward rewriting data is in a "pack" operation, such as the one Git has. It wouldn't be terribly crazy to consider a standalone pack operation in a DVCS to be better than rewriting data for each commit, for several reasons:
- It allows us to keep commit fast.
- Since pack would be done offline, its implementation can
be focused more on data integrity and space savings than on performance.
- Since the pack code can be separated from the commit code,
all the risky code can be kept together where it is easier to maintain.
- Since the pack operation is separate from commit, a user
that does not want to run pack does not have to.
- A pack operation in a DVCS is happening on just one instance (clone) of the repository, not on the only copy.
Anyway, a pack operation would allow us to use storage schemes that do not work well on the fly, incrementally updating as each version comes in.
Visualizing the results
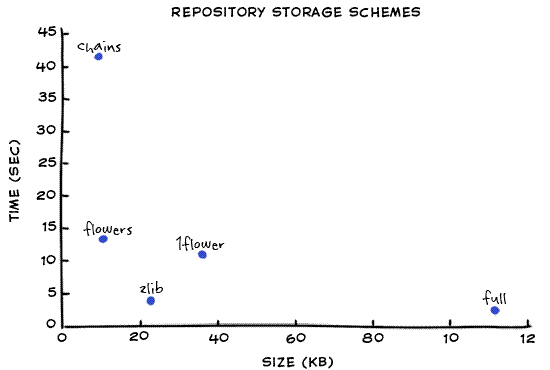
This plot makes it easier to see which schemes are better than others.
In my experimentation, I actually did a lot more schemes. For example, instead of key frames every 10 versions, I also tried every 5, 15 and 20. However, all those extra data points really cluttered the graph. So I only included the most important ones here.
- In the lower right, we find "full". Very fast and very
large.
- In the upper left, we find "chains". Very slow and very
small.
- We can ignore any point which is both above AND to the
right of any other point. The "1flower" point is the one where I made one
big flower, using version 1 as the reference for every other version.
This scheme ends up being useless since zlib is better in both ways that
matter.
- All the other points represent possible tradeoffs which might be interesting, depending upon our priorities
Intuitively, the schemes which are closer to the origin are better. This graph makes it easy to see that "zlib" and "flowers" are probably the two most interesting options I have discussed here.