
2009-03-02 16:10:25
DVCS and DAGs, Part 1
There are two kinds of people:
- Those who tend to divide everything into two groups
- Those who do not.
I am one of the former. :-)
There are two kinds of version control tools:
- Those where the history is a Line.
- Those where the history is a Directed Acyclic Graph (a DAG).
Traditional tools (like Subversion and Vault) tend to model history as a Line. In the DVCS tools (like Git and Mercurial), history is a DAG. The differences between these two models are rather interesting.
The Line model is tried and true. History is a sequence of versions, one after the other.
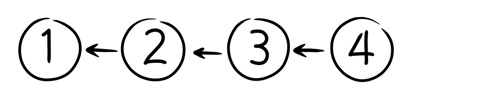
To create a new version:
- Grab the latest version
- Make some changes to it
- Check it back in
People like the Line model for its simplicity. It provides an unambiguous answer to the question of which version is latest.
But the Line model has one big problem: You can only checkin a new version if it was based on the latest version. And this kind of thing happens a lot:
- I grab the latest version. At the time I grabbed it, this was version 3.
- I make some changes to it
- While I am doing this, somebody checks in version 4.
- When I go to checkin my changes, I can't, because they are not based on the current version. The "baseline" for my changes was version 3, because that's what was current when I started.
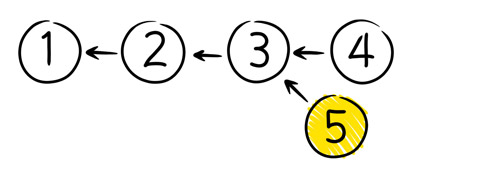
The Line model of history won't allow me to create version 5 as shown in the picture. Instead, a Line model SCM tool will require me to take the changes which were made between version 3 and 4 and apply them to my version. This operation is usually called a "merge". The result is that my baseline gets changed from 3 to 4, thus allowing me to checkin. This model is explained in chapter 2 of my SourceControl HOWTO as "edit-merge-commit".
The obvious question is: What would happen if we allowed 5 to be checked in with 3 as its baseline? Our history would no longer be a Line. Instead it would be a DAG.
And why would we do this?
The major feature of the DAG model for history is that it doesn't interrupt the developer at the moment they are trying to commit their work. In this fashion, the DAG is probably a more pure representation of what happens in a team practicing concurrent development. Version 5 was in fact based on version 3, so why not just represent that fact?
Well, it turns out there is a darn good reason why not. In the DAG above, we don't know which version is "the latest". This causes all kinds of problems:
- Suppose we need the changes in version 4 and 5 in order to ship our release. Currently we can't have that. There is no version in the system that includes both.
- Our build system is configured to always build the latest version. What is it supposed to do now?
- Even if we build both 4 and 5, which one is QA supposed to test?
- If a developer wants to update her tree to the latest version, which one is it?
- When a developer wants to make some changes, which version should they use as the baseline?
- Our project manager wants to know which tasks are done and how much work is left to do. His notion of "done" is very closely associated with the concept of "latest". If he can't figure out which version is latest, his brain is likely to just blue screen when he tries to update the Gannt chart.
Yep, this is a bad scene. Civilization as we know it will probably just shut down.
In order to avoid dogs and cats living together with mass hysteria, the tools that use a DAG model of history provide a way to resolve the mess. The answer is the same as it is with Line history. We need a merge. But instead of requiring the developer to merge before they commit, we allow that merge to happen later.
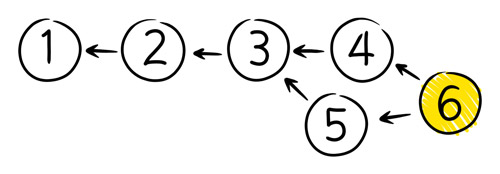
Somebody needs to construct a version which contains all the changes in both version 4 and version 5. When this version gets committed, it will have arrows pointing to both of its "parents".
Order has been restored. Once again we know which version is "the latest". If somebody will remember to reboot the project manager, he will probably realize that this DAG looks almost like a Line. Except for that weird stuff happening between version 3 and 6, it is a Line. Best not to lose sleep over it.
What this project manager doesn't know is that this particular crisis was minor. He thinks that his paradigm has been completely challenged, but one day he's going to come into his office and find this:
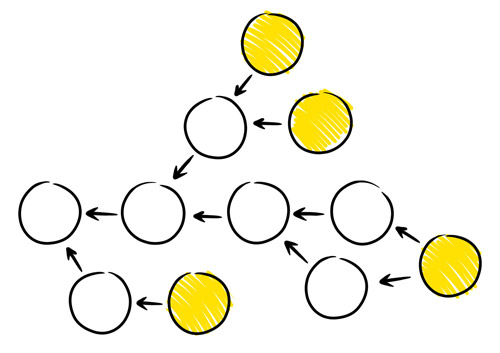
&@#$!
Now what?
If you're living in the Line model paradigm, this DAG is an absolute disaster. It has FOUR leaf nodes. Everything that needs to know which version is latest is about to completely fall apart, including the aforementioned product manager who is probably now in his office curled up in a fetal position and hoping that Mommy includes cookies with his SpaghettiOs at lunch.
The Line model is looking pretty good right now. There's a good reason why 99.44% of developers are using an SCM tool built on the Line model of history. (Yes, I made that statistic up.)
And yet, despite all this apparent chaos, we should remind ourselves of the primary benefit of the DAG model: It more accurately describes the way developers work. It doesn't make developers bend to its will like the Line model does. When a developer wants to check something in, he does, and the DAG merely records what happened.
Many teams will always prefer the Line model, and there's nothing wrong with that. Life is simpler that way.
But for some other teams, the DAG model can be really valuable.
And for other teams, the DAG model might be coming along simply because they want to use a DVCS tool for other reasons. DVCS tools use a DAG because they have to. If we can't assume a live connection to a central server, there isn't any way to force developers to make everything fit into the Line model.
So we need to figure out ways of coping with the DAG. How do we do this?
One way is to reframe every operation. If you tell a doctor that "it hurts when I need to know which version is latest", the doctor will tell you to "stop doing that". Instead, always specify exactly which node to use:
- The build machine doesn't build the latest node. Instead, it builds whichever node we tell it to build. Or maybe it builds every node.
- QA tests whichever build somebody decides they should test.
- Developers don't update their tree to "the latest". Instead, they look at the DAG, pick a node, and update to that one.
I'm not saying this approach is practical. I am merely observing that it is conceptually valid. As long as you're willing to specify which node you want to use, any operation that needs a node can proceed.
But how do we specify a node? One thing that makes this approach problematic is that these nodes tend to have odd names. For example, in Git, the name of a node is something like e69de29bb2d1d6434b8b29ae775ad8c2e48c5391. Developers are going to find this naming scheme to be a little unintuitive.
All DVCS tools use a DAG. And all these tools do various things to either prevent "the crisis of multiple leaf nodes" or to help the team cope with it. But they all seem to do it a little differently.
Happily, this presents me with an opportunity to divide them all into two groups:
- Those who handle this problem in ways that I like.
- Those who handle this problem in ways that I do not like.
This blog entry is already longer than I thought it would be, so I'm going to stop here and continue next week.