In order to support the ability to push and pull changesets between multiple instances of the same repository, we need a specially designed structure for representing multiple versions of things. The structure we use is called a Directed Acyclic Graph (DAG), a design which is more expressive than a purely linear model. The history of everything in the repository is modeled as a DAG.
Second generation tools tend to model the history of a repository as a line. The linear history model is tried and true. History is a sequence of versions, one after the other, as shown in Figure 4.3, “Repository History as a Line”.
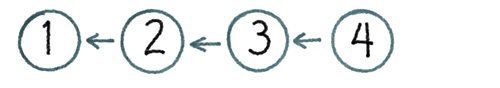
To create a new version:
-
Grab the latest version
-
Make some changes to it
-
Check it back in
People like linear history for its simplicity. It provides an unambiguous answer to the question of which version is latest.
But the linear model has one big problem: You can only commit a new version if it was based on the latest version. And this kind of thing happens a lot:
-
I grab the latest version. At the time I grabbed it, this was version 3.
-
I make some changes to it.
-
While I am doing this, somebody commits version 4.
-
When I go to commit my changes, I can’t, because they are not based on the repository’s current version. The parent for my changes was version 3 because that’s what was current when I started.
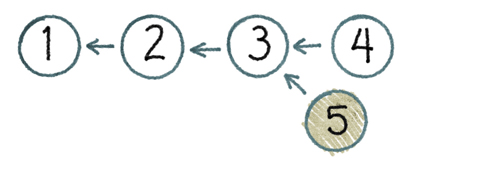
The linear model of history won’t allow me to create version 5 as shown in Figure 4.4, “Not a Line”. Instead, a linear history VCS requires me to take the changes which were made between versions 3 and 4 and apply them to my version. The result is that my working copy’s parent gets changed from 3 to 4, thus allowing me to commit.
This is unfortunate. My changes were made against version 3, but now they are getting blended with the changes from version 4. What if they don’t blend well?
The obvious question is: What would happen if we allowed 5 to be checked in with 3 as its parent? Our history would no longer be a line. Instead it would be a Directed Acyclic Graph (DAG).
A DAG is a data structure from computer science which can be used to model a wide variety of problems. The DAG consists of the following elements:
-
Nodes. Each node represents some object or piece of data. In the case of a DVCS, each node represents one revision of the entire repository tree.
-
Directed edges. A directed edge (or “arrow”) from one node to another represents some kind of relationship between those two nodes. In our situation, the arrow means “is based on”. By convention, I draw DAG arrows from child to parent, from the new revision to the revision from which it was derived. Arrows in a DAG may not form a cycle.
-
A root node. At least one of the nodes will have no parents. This is the root of the DAG.
-
Leaf nodes. One or more of the nodes will have no children. These are called leaves or leaf nodes.
A major feature of the DAG model for history is that it doesn’t interrupt the developer at the moment she is trying to commit her work. In this fashion, the DAG is probably a more pure representation of what happens in a team practicing concurrent development. Version 5 was in fact based on version 3, so why not just represent that fact?
Well, it turns out there is a darn good reason why not. In the DAG above, we don’t know which version is “the latest”. This causes all kinds of problems:
-
Suppose we need the changes in versions 4 and 5 in order to ship our release. Currently we can’t have that. There is no version in the system that includes both.
-
Our build system is configured to always build the latest version. What is it supposed to do now?
-
Even if we build both 4 and 5, which one is QA supposed to test?
-
If a developer wants to update her working copy to the latest version, which one is it? When a developer wants to make some changes, which version should he use as the baseline?
-
Our project manager wants to know which tasks are done and how much work is left to do. His notion of “done” is very closely associated with the concept of “latest”. If he can’t figure out which version is latest, his brain is likely to just blue screen when he tries to update the Gantt chart.
Yep, this is a bad scene. Civilization as we know it will probably just shut down.
In order to avoid dogs and cats living together with mass hysteria, the tools that use a DAG model of history provide a way to resolve the mess. The answer is the same as it is with linear history. We need a merge. But instead of requiring the developer to merge before committing, we allow that merge to happen later.
Somebody needs to construct a version which contains all the changes in both version 4 and version 5. When this version gets committed, it will have arrows pointing to both of its “parents” as shown by version 6 in Figure 4.5, “Sort of like a Line”.
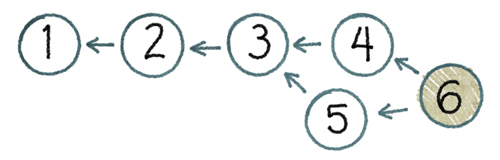
Order has been restored. Once again we know which version is “the latest”. If somebody bothers to reboot the project manager, he will probably realize that this DAG looks almost like a line. Except for that weird stuff happening between versions 3 and 6, it is a line. Best not to lose sleep over it.
What this project manager doesn’t know is that this particular crisis was minor. He thinks that his paradigm has been completely challenged, but one day he’s going to come into his office and find something like the picture in Figure 4.6, “Not even close to being a Line”.
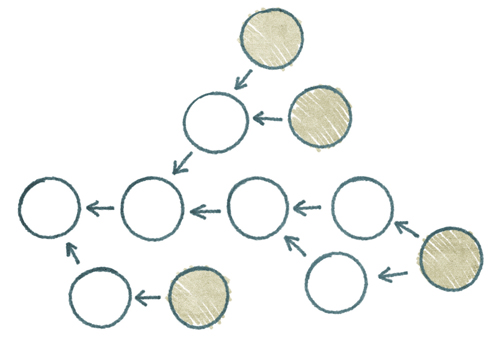
Now what? If you’re living in the linear history paradigm, this DAG is an absolute disaster. It has four leaf nodes. Everything that needs to know which version is latest is about to completely fall apart, including the aforementioned product manager who is probably now in his office curled up in a fetal position and hoping that Mommy included cookies with his SpaghettiOs for lunch.
The linear history model is looking pretty good right now. There’s a good reason why 99.44% of developers are using a version control tool built on the notion of history as a line. (Yes, I made that statistic up.)
And yet, despite all this apparent chaos, we should remind ourselves of the primary benefit of the DAG model: It more accurately describes the way developers work. It doesn’t make developers bend to its will like the linear model does. When a developer wants to check something in, she does, and the DAG merely records what happened.
Many teams will always prefer the linear history model, even if it requires them to make their development process compatible with it, and there’s nothing wrong with that. Life is simpler that way.
But the DAG model is more flexible and expressive, and many teams can benefit from a VCS which has those qualities.
And for other teams, the DAG model might be coming along simply because they want to use a DVCS tool for other reasons. DVCS tools use a DAG because they have to. If we can’t assume a live connection to a central server, there isn’t any way to force developers to make everything fit into the linear model.
So we need to figure out ways of coping with the DAG. How do we do this?
One way is to reframe every operation. If you tell a doctor that “it hurts when I need to know which version is latest”, the doctor will tell you to “stop doing that”. Instead, always specify exactly which node to use:
-
The build machine doesn’t build the latest node. Instead, it builds whichever node we tell it to build. Or maybe it builds every node.
-
QA tests whichever build somebody decides they should test.
-
Developers don’t update their tree to “the latest”. Instead, they look at the DAG, pick a node, and update to that one.
I’m not saying this approach is always practical. I am merely observing that it is conceptually valid. If you want your DAG to have multiple leaf nodes, you can do that. As long as you’re willing to specify which node you want to use, any operation that needs a node can proceed.
In practice, the most common solution to this problem is to have stricter rules about the shape of the DAG on the central server. In other words, developers are allowed to have all manner of DAG chaos in their private repository instances, but the DAG on the central server must have a single leaf node.
Typically, a DVCS will warn you if you are attempting a push which would make the remote repository’s DAG messy. Users of Mercurial and Veracity would typically handle this situation by doing a pull, then a merge, and then retrying the push.
Git users often handle this situation differently, using Git’s rebase feature. Rebase is a way of rewriting changesets, replacing them with new ones that are exactly equivalent but which have different parents. The way this feature is typically used is to rewrite DAG history as a line. In other words, even though Git is clearly a third generation version control tool, many of its users prefer the cleaner, linear history of a second generation tool.
Because Git’s rebase command alters things which have already been committed to a repository instance, it often serves as a launching point for arguments among DVCS fans with different perspectives on the immutability of a repository instance.
One final note about DAGs: It would be conceptually valid to use the notion of a DAG to discuss the divergence of any part of a repository. However, when we speak of a DAG with respect to a DVCS, we’re talking about the whole tree. This is how branching works in DVCS land—each node of the DAG is a version of the whole tree. This contrasts with CVCS tools where most popular implementations model a branch as a directory in the tree which was branched from another directory in the tree.